Building Better Ethereum Infrastructure

It’s been four weeks since three thousand builders and creators converged in Osaka to attend Devcon V: the annual conference for Ethereum developers. Across three days the Ethereum community came together to exchange ideas, attend workshops and be inspired by a range of electric talks. On day two, Infura founder Eleazar Galano and Senior Systems Engineer Jee Choi delivered a talk on Infura’s Open Architecture Initiative. The Initiative is an ongoing effort to consolidate the knowledge and experience Infura has accumulated as Ethereum’s largest blockchain infrastructure provider, and share it with the developer community.
Opening Up to Create a Stronger Ecosystem
Some of the problems we’ve worked through to bring reliability and scale to our infrastructure are common to many Ethereum developers. Even basic node deployments require additional tooling to maintain a minimum level of reliability. The solutions we’ve implemented can also help others build better architecture. Through the Open Architecture Initiative, we’re providing visibility into Infura’s architecture. We encourage other organisations to do the same and share what isn’t proprietary to increase collaboration, solve problems faster and benefit the entire ecosystem.
This post steps through the evolution of Infura’s architecture to share how we’ve scaled reliable access to the Ethereum network and gives readers a sneak peek into what’s coming next.
Infura was launched three years ago, at Devcon II, with a mission: to make a valuable contribution to the Ethereum ecosystem by removing the infrastructure burden from developers, so they could focus on building great Web3 software. Over the last three years our architecture has evolved to serve the growing demands of our user base. Ethereum client software is engineered to be accessible and ubiquitous. While at its core Infura has always been powered by that same public client software, we have augmented and optimized our architecture to fully take advantage of the resources available in a modern cloud environment, to provide the most stable and scalable experience possible.
Single Node Architecture
Most developers start building on Web3 by spinning up a single node or ‘client’. Whether they’re an engineer working for a large enterprise, a developer building their own dapp or part of a development team looking to scale their project to support more users, all developers use the same nodes.
A single node will connect an application to a peer-to-peer (P2P) network, but it limits the extent to which that application can scale. Once they’ve surpassed the scaling requirements of a single node, developers need to implement custom solutions to unblock further growth. Unfortunately, that means that teams with more resources have an advantage over single developers and end up creating better sources of data for their apps. By sharing some of the design patterns and tools we’ve implemented to build Infura, we hope to level the playing field a bit more. for development teams.
Client Types
The most common Ethereum clients (‘nodes’) are Geth (go-ethereum), Parity-Ethereum and Hyperledger Besu. A standard Ethereum client is monolithic. It is comprised of various subsystems which can only be scaled to a certain degree:
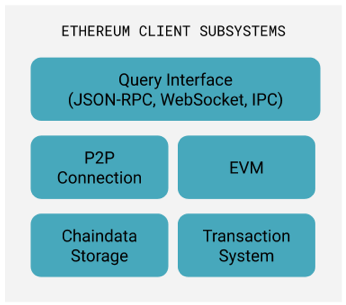
This results in two key friction points for developers:
- This monolithic architecture means that most people need to build custom software solutions around the client in order to enable a particular use case (rather than simply optimizing the client for that use case);
- A common way to run a resilient web service is via high-availability and redundancy patterns which means you can have separate failure domains for these subsystems and can optimize them independently. However, an Ethereum client is only as reliable as the server or hardware it is running on. If the client fails, all of its subsystems become inaccessible. An example of this is the local key-value data store or the RPC server:
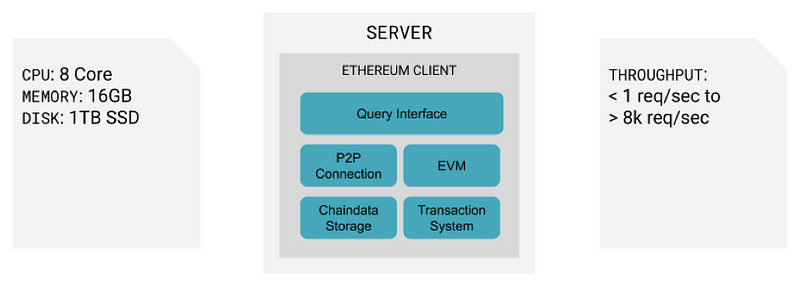
Infura’s Cloud Architecture Model
In 2016, Infura started running an Ethereum client on our cloud infrastructure. This enabled us to provision a new virtual server, install the Ethereum client software and sync the chain up to the most recent block data (also known as ‘node provisioning’). This method resulted in faster sync times between nodes (< 1 hour) and removed the need for additional tooling.

To ensure we could maintain a shorter sync time, we moved to using snapshots of EBS chain data. If sync time crossed a particular threshold, we considered it too long and spun up a new node, quickly to keep our systems operational. Snapshots enabled this process, ensuring no downtime for our service. Bonus: periodic snapshots were also valuable for failure recovery.
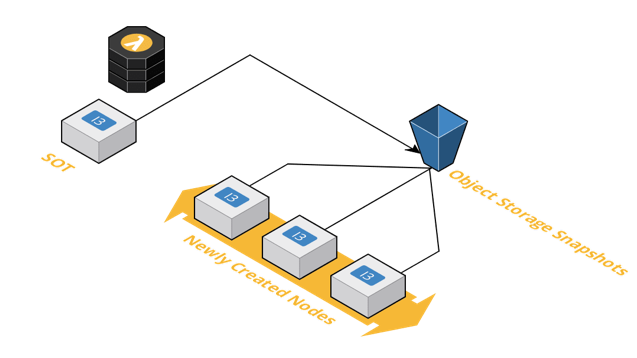
Optimizations in Space and Time
This particular implementation of the client storage system resulted in major performance improvements with the release of Geth v1.9.0. Sync time was reduced by 6.4 hours and the amount of disk space needed to store the chain was also optimized:

Increased Input/Output Operations Per Second (IOPS)
As Table a) demonstrates, a substantial volume of data is written and read when you’re running a node and syncing the chain (over 1 TiB). For a server, this is typically measured in increased Input/Output Operations Per Second (IOPS). Higher IOPS means that your node will not be bottlenecked by disk input/output when syncing the chain. We chose Amazon EC2 (i3 instance class) as our server for running nodes because of the direct access to high IOPS capable Solid-State Drives (SSDs). This resulted in fast SSD direct syncing from object storage for Archive and Full Sync nodes.
Traffic Patterns
We’ve classified Infura’s traffic into three categories: Near-Head (within a couple of hundred blocks behind latest), Archive (need pruned data) and Full (do not need pruned data):
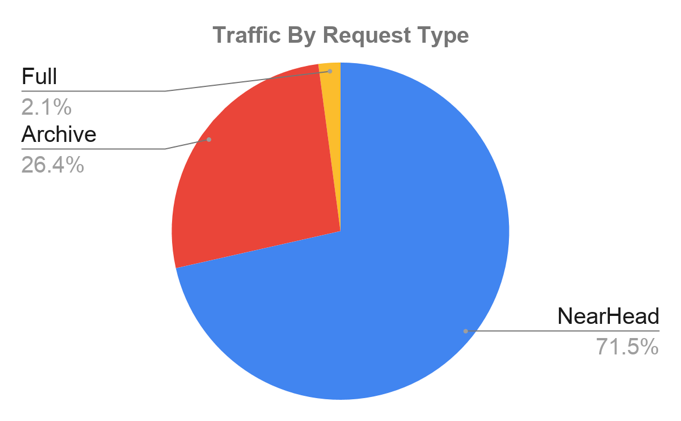
The majority of our traffic is Near-Head (consistently more than 70%). Archive traffic is pretty fluid and frequently varies between 26. 4% and 1%. To service the high volume of Near-Head traffic, we started caching the data (‘Near-Head Cache’) using a Content Delivery Network (CDN). This worked well in the beginning, but we found it to be limited. Traffic continued to grow, and we reached a point where the CDN constrained us. We then switched to a Redis database which allowed us to cache all our Near-Head data and enabled us to scale.
Specialized Microservices
Log Indexer
We use a variety of different, specialized indexers and caching methods to help us handle frequently called requests. ‘Log Indexer’ is one of them. Infura receives a ton of get_logs requests. Traditionally, an Ethereum client uses bloom filters to retrieve getLog data. This works well in single user scenarios, but if you’re handling a lot of requests, it can be really time consuming. Using bloom filters for retrieval would have increased load time and slowed down response times. We built Log Indexer to solve this problem. It indexes all log data with incoming new blocks, allowing for faster retrieval and overall higher quality of service for those types of requests.
What About Re-Orgs?
To detect re-orgs, we built a ‘Re-Org Tracker’: a microservice that detects re-orgs with incoming block data:

The tracker offloads rollback events associated with re-org’d block and retrieves the correct canonical block data. It might look like a simple system, but it can be used to index any data associated with blocks.
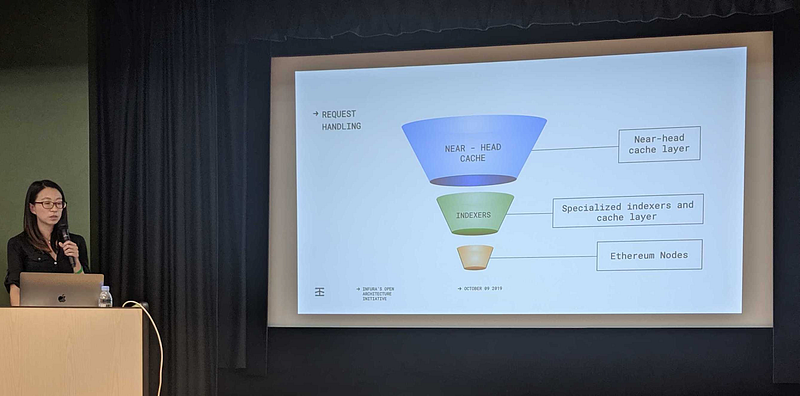
Request Handling
This is a general overview of how Infura handles traffic:
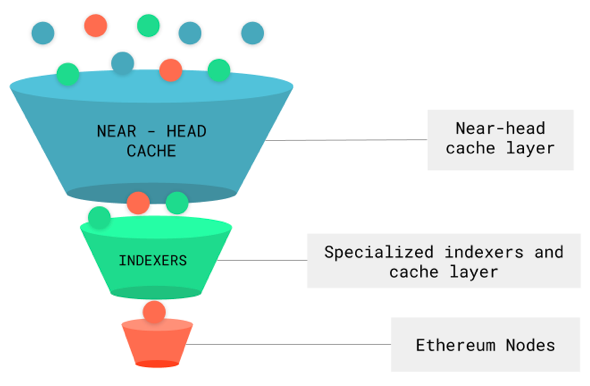
Most of our traffic is handled Near-Head caching. We then have a set of specialized indexers and caches that handle more frequently called requests and finally, full sync and archive nodes serve are set up to serve a very small amount of infrequent requests.
Internal Tools
- Key router / Consistent-Hashing: we open-sourced Infura’s keyrouter microservice, which uses consistent-hashing to map keys to a set of data sources (endpoints) consistently. This is really useful for routing specific kinds of traffic to particular data sources.
- Peering Manager: a member of our team, Andrey Petrov, created a service called Vipnode which connects nodes with desired peers, such as light-nodes to full nodes. Infura uses Vipnode to create separate internal node topologies grouped by various attributes. It helps control block propagation times and bandwidth utilization of nodes.
- Node Monitor: to track the health of Infura’s nodes, we implemented a node monitoring service. It keeps track of critical stats — like block number or number of peers, for example — and restarts our nodes as required.
A Sneak Peak at What’s Coming Next
We continue to be dedicated to working closely with the Ethereum ecosystem and sharing what we’ve learned to make base network access as easy as possible to run and scale. In the meantime, we’ve roadmapped a ton of new projects and features based on user feedback and some new tech! Here’s a quick preview of what we’ll be rolling out:
- Official support for trace methods;
- Expanding support for gas interactions with some potentially exciting partnerships;
- Full suite of transaction tools to help developers create stellar user experiences;
- Enriching the Infura Dashboard to add some of our top requested features (more on this soon!);
- Supporting more Web3 technologies! We’ve just wrapped up a project with the POA team supporting xDAI and Splunk to launch ButterCup Bucks at Splunk Conference 2019. This is just one of many collaborative Web3 projects currently in our backlog. We’re looking forward to adding value to more awesome projects across the Web3 sphere.